Programação de Redes
Introdução:
Inicialmente precisa conceituar o que é socket. A comunicação entre processos de software tornou-se indispensável nos sistemas atuais.
O elo entre os processos do servidor e do cliente é o socket. Ele é a “porta” na qual os processos enviam e recebem mensagens. De acordo com JAMES F KUROSE: “socket é a interface entre a camada de aplicação e a camada de transporte dentro de uma máquina”.
Então foram desenvolvidas diversas aplicações cliente/servidor onde cliente(s) e servidor poderiam estar em máquinas diferentes, distantes umas das outras. Os aplicativos do cliente e do servidor utilizam protocolos de transporte para se comunicarem. Quando um aplicativo interage com o software de protocolo, ele deve especificar detalhes, como por exemplo se é um servidor ou um cliente. Além disso, os aplicativos que se comunicam devem especificar detalhes adicionais (por exemplo, o remetente deve especificar os dados a serem enviados, e o receptor deve especificar onde os dados recebidos devem ser colocados).
Analisando o esquema acima percebemos que tudo acima da interface do socket, na camada de aplicação, é controlado pelo criador da aplicação. O controle da camada de transporte é feito pelo Sistema Operacional.
Temos dois tipos de serviços de transporte via socket: o confiável orientado a cadeia de bytes (byte steam) e os datagramas não confiáveis. O protocolo na qual é implementado o primeiro é o TCP, já o segundo é implementado no protocolo UDP.
Padrão de arquitetura Reactor e Proactor (Reativo e Proativo)
Reactor:
"Um padrão comportamental de objeto para desmultiplexação e distribuição de identificadores para eventos síncronos." - Douglas C. Schmidt
O padrão de arquitetura do Reactor permite que aplicativos controlados por eventos desmultiplexem e despachem solicitações de serviço que são entregues a um aplicativo por um ou mais clientes. A estrutura introduzida pelo padrão do Reactor inverte o fluxo de controle dentro de um aplicativo.
É responsabilidade de um componente designado, chamado reactor, não um aplicativo, aguardar eventos de indicação de forma síncrona, desmultiplexá-los para manipuladores de eventos associados que são responsáveis pelo processamento desses eventos e, em seguida, despachar o método de gancho apropriado no manipulador de eventos. Em particular, um reactor despacha manipuladores de eventos que reagem à ocorrência de um evento específico. Portanto, os desenvolvedores de aplicativos são responsáveis apenas pela implementação de manipuladores de eventos concretos e podem reutilizar os mecanismos de desmultiplexação e despacho do reactor. Embora o padrão do Reactor seja relativamente simples de programar e usar, ele possui várias restrições que podem limitar sua aplicabilidade. Em particular, ele não é dimensionado para suportar um grande número de clientes simultâneos e/ou solicitações de clientes de longa duração, pois serializa todo o processamento do manipulador de eventos na camada de desmultiplexação de eventos.
Para ilustrar o padrão do Reactor, considere o servidor acionado por eventos para um serviço de log distribuído mostrado na Figura abaixo. Os aplicativos clientes usam o serviço de log para registrar informações sobre seu status em um ambiente distribuído. Essas informações de status geralmente incluem notificações de erro, rastreamentos de depuração e relatórios de desempenho. Os registros de log são enviados para um servidor de log central, que pode gravar os registros em vários dispositivos de saída, como um console, uma impressora, um arquivo ou um banco de dados de gerenciamento de rede.
O servidor de log lida com registros de log e solicitações de conexão enviadas pelos clientes. Registros de log e solicitações de conexão podem chegar simultaneamente em vários identificadores. Um identificador identifica os recursos de comunicação de rede gerenciados em um SO.
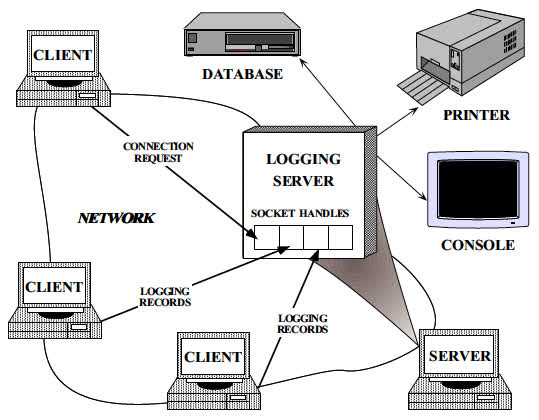
Figura 1: Serviço de Log Distribuído
O servidor de log se comunica com os clientes usando um protocolo orientado a conexão, como o TCP. Os clientes que desejam registrar dados devem primeiro enviar uma solicitação de conexão ao servidor. O servidor aguarda essas solicitações de conexão usando um identificador de fábrica que escuta em um endereço conhecido pelos clientes. Quando uma solicitação de conexão chega, a fábrica de identificadores estabelece uma conexão entre o cliente e o servidor, criando um novo identificador que representa um ponto de extremidade da conexão. Esse identificador é retornado ao servidor, que aguarda as solicitações de serviço ao cliente chegarem no identificador. Depois que os clientes estão conectados, eles podem enviar registros simultaneamente ao servidor. O servidor recebe esses registros através dos identificadores de soquete conectados.
Talvez a maneira mais intuitiva de desenvolver um servidor de log simultâneo seja usar vários threads que possam processar vários clientes simultaneamente, como mostra abaixo. Essa abordagem aceita sincronicamente conexões de rede e gera um thread por conexão para manipular os registros de log do cliente.
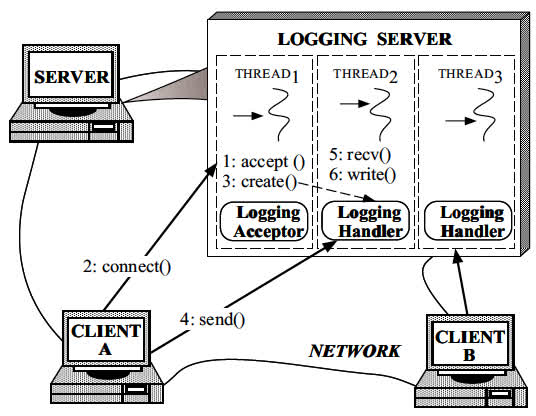
Figura 2: Servidor de log multithread
No entanto, o uso de multithread para implementar o processamento de registros de log no servidor falha ao resolver as seguintes forças:
- Eficiência: a thread pode levar a um desempenho ruim devido à alternância de contexto, sincronização e movimentação de dados;
- Simplicidade de programação: a thread pode exigir esquemas complexos de controle de simultaneidade;
- Portabilidade: a thread não está disponível em todas as plataformas de SO.
Proactor:
"Um Padrão Comportamental de Objetos para desmultiplexar e despachar manipuladores para eventos assíncronos." - Douglas C. Schmidt
O padrão de arquitetura Proactor permite que os aplicativos controlados por eventos desmultiplexem e despachem solicitações de serviços com eficiência, acionadas pela conclusão de operações assíncronas. Oferece os benefícios de desempenho da simultaneidade sem incorrer em alguns de seus passivos.
No padrão Proactor, os componentes do aplicativo são representados por clientes e manipuladores de conclusão que são entidades proativas. Diferentemente do padrão Reactor, que espera passivamente a chegada de eventos de indicação e reage, clientes e manipuladores de conclusão no padrão Proactor instigam o controle e o fluxo de dados dentro de um aplicativo iniciando uma ou mais solicitações de operação assíncrona proativamente em um processador de operação assíncrono.
Quando essas operações assíncronas são concluídas, o processador de operação assíncrona e um componente proactor designado colaboram para desmultiplexar os eventos de conclusão resultantes para seus manipuladores de conclusão associados e despachar os métodos de gancho desses manipuladores. Após o processamento de um evento de conclusão, um manipulador de conclusão pode iniciar novas solicitações de operação assíncrona de maneira proativa.
O padrão Proactor deve ser aplicado quando os aplicativos exigirem os benefícios de desempenho da execução simultânea de operações, sem as restrições síncrona ou reativa ou multithread. Para ilustrar esses benefícios, considere um aplicativo de rede que precise executar várias operações simultaneamente. Por exemplo, um servidor Web de alto desempenho deve processar simultaneamente solicitações HTTP enviadas de vários clientes. A Figura abaixo mostra uma interação típica entre navegadores Web e um servidor Web. Quando um usuário instrui um navegador a abrir uma URL, ele envia uma solicitação HTTP GET ao servidor da Web. Após o recebimento, o servidor analisa e valida a solicitação e envia os arquivos especificados de volta ao navegador.
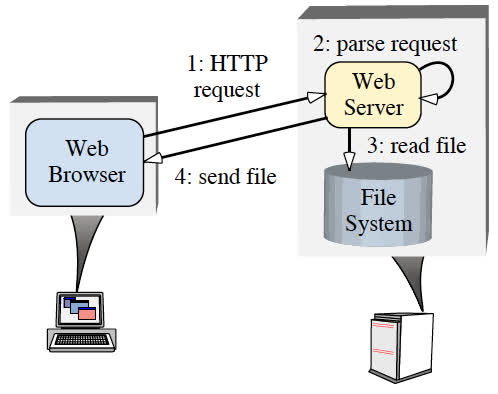
Figura 3: Arquitetura típica de software de comunicação para servidor Web
O desenvolvimento de servidores Web de alto desempenho requer a resolução das seguintes forças:
- Simultaneidade: O servidor deve executar várias solicitações do cliente simultaneamente;
- Eficiência: O servidor deve minimizar a latência, maximizar a taxa de transferência e evitar a utilização desnecessária da CPU.
- Simplicidade de programação: O design do servidor deve simplificar o uso de estratégias de concorrência eficientes;
- Adaptabilidade: A integração de protocolos de transporte novos ou aprimorados (como HTTP 1.1) deve resultar em custos mínimos de manutenção.
Um servidor Web pode ser implementado usando várias estratégias de simultaneidade, incluindo várias threads síncronos, envio de evento síncrono reativo e envio de evento assíncrono proativo. Abaixo, examinamos as desvantagens das abordagens convencionais e explicamos como o padrão Proactor fornece uma técnica poderosa que suporta uma estratégia eficiente e flexível de despacho de eventos assíncronos para aplicativos simultâneos de alto desempenho.
Acceptor-Connector:
O padrão de projeto Acceptor-Connector desacopla a conexão e a inicialização dos serviços de ponto de cooperação em um sistema em rede do processamento que eles executam depois de conectados e inicializados. O Acceptor-Connector permite que os aplicativos configurem suas topologias de conexão de uma maneira amplamente independente dos serviços que eles fornecem. O padrão pode ser colocado em camadas na parte superior do Reactor para manipular eventos associados ao estabelecimento da conectividade entre serviços.
Reactor vs Proactor:
Em geral, os mecanismos de multiplexação de E/S dependem de um desmultiplexador de eventos, um objeto que despacha eventos de E/S de um número limitado de fontes para os manipuladores de eventos de leitura e gravação apropriados. O desenvolvedor registra interesse em eventos específicos e fornece manipuladores de eventos ou retornos de chamada. O desmultiplexador de eventos entrega os eventos solicitados aos manipuladores de eventos.
Dois padrões que envolvem desmultiplexadores de eventos são chamados Reactor e Proactor. Os padrões do reactor envolvem E/S síncrona, enquanto o padrão Proactor envolve E/S assíncrona. No Reactor, o desmultiplexador de eventos aguarda os eventos que indicam quando um descritor ou socket de arquivo está pronto para uma operação de leitura ou gravação. O desmultiplexador passa esse evento para o manipulador apropriado, responsável por executar a leitura ou gravação real.
No padrão Proactor, por outro lado, o manipulador ou o desmultiplexador de eventos em nome do manipulador e inicia operações de leitura e gravação assíncronas. A própria operação de E/S é executada pelo sistema operacional (SO). Os parâmetros passados para o sistema operacional incluem os endereços dos buffers de dados definidos pelo usuário, dos quais o sistema operacional obtém dados para gravação ou nos quais o sistema operacional coloca dados lidos. O desmultiplexador de eventos aguarda eventos que indicam a conclusão da operação de E/S e encaminha esses eventos para os manipuladores apropriados. Por exemplo, no Windows, um manipulador pode iniciar operações de E/S assíncronas (sobrepostas na terminologia da Microsoft), e o desmultiplexador de eventos pode esperar pelos eventos de IOCompletion. A implementação desse padrão assíncrono é baseada em uma API assíncrona no nível do SO, e chamaremos essa implementação de assíncrona "no nível do sistema" ou "true", porque o aplicativo depende totalmente do SO para executar a E/S real.
Um exemplo ajudará você a entender a diferença entre o Reactor e o Proactor. Vamos nos concentrar na operação de leitura aqui, pois a implementação de gravação é semelhante. Aqui está uma leitura no Reactor:
- Um manipulador de eventos declara interesse em eventos de E/S que indicam prontidão para leitura em um socket específico
- O desmultiplexador de eventos aguarda eventos
- Um evento chega e ativa o desmultiplexador e o desmultiplexador chama o manipulador apropriado
- O manipulador de eventos executa a operação de leitura real, manipula a leitura de dados, declara interesse renovado em eventos de E/S e retorna o controle ao expedidor.
Por comparação, aqui está uma operação de leitura no Proactor (true async):
- Um manipulador inicia uma operação de leitura assíncrona (nota: o sistema operacional deve suportar E/S assíncrona). Nesse caso, o manipulador não se importa com eventos de prontidão de E/S, mas, em vez disso, registra o interesse em receber eventos de conclusão.
- O desmultiplexador de eventos aguarda até que a operação seja concluída
- Enquanto o desmultiplexador de eventos aguarda, o SO executa a operação de leitura em um thread paralelo do kernel, coloca os dados em um buffer definido pelo usuário e notifica o desmultiplexador de eventos de que a leitura está concluída
- O desmultiplexador de eventos chama o manipulador apropriado;
- O manipulador de eventos manipula os dados do buffer definido pelo usuário, inicia uma nova operação assíncrona e retorna o controle ao desmultiplexador de eventos.
Fonte: POSA2